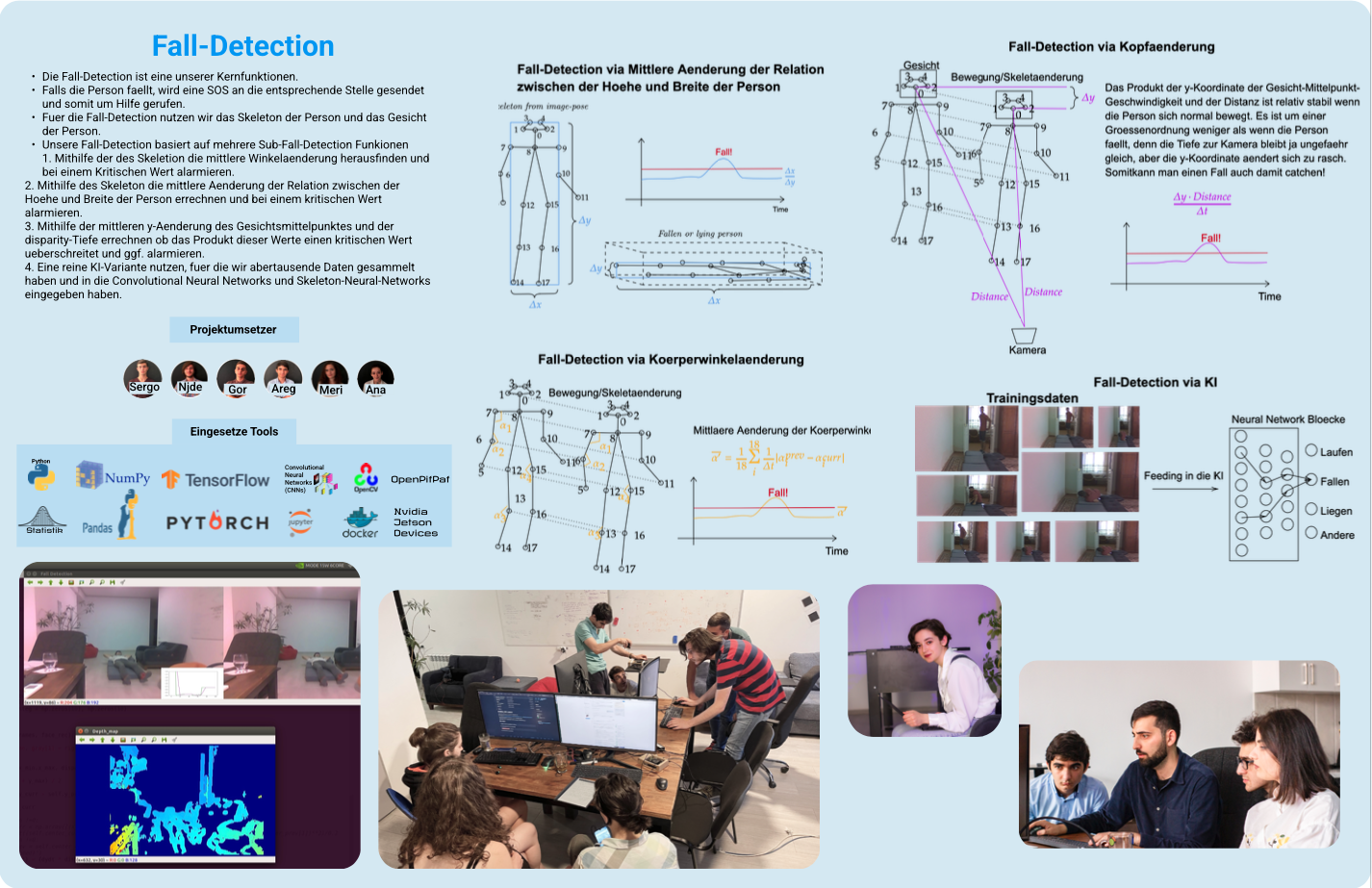
Project: Fall Detection
Development of Fall detection Machine Learning Algorithms for a Smart Vision Assistant.
- Collect data of human skeleton in various fall scenarios via motion capture and skeleton detection algorithms.
- Balance the dataset with fall and non-fall scenarios to ensure that the machine learning algorithm can distinguish between normal and abnormal movements.
- Feature Extraction: relevant features extracted from skeleton data to represent the movement patterns: joint angles, joint velocities, and acceleration
- Data saved on AWS S3 bucket.
- Extracted features used to create matrices which were fed into a machine learning algorithm.
- Used AWS AutoML to find best ML model.
Tech Stack: Python, Scikit-learn, OpenCV, Pytorch, Image-Pose, AWS, Sagemaker, AutoML, AutoPilot, Cuda, Linux, Git, Pytest.
Project: Voice ReID, Voice to Text
Development of speech recognition system that can identify the speaker and transcribe the language from audio data.
- Audio data divided into 4-second segments sampled at 16kHz.
- Feature extraction techniques on audio data, such as MFCCs, Mel-scale spectrogram, chromagram, spectral contrast, and tonnetz, based on STFT, utilizing Kaldi.
- Utilizing Scikit-learn for feature clustering.
- Utilizing FFT (Fast Fourier Transformation) for denoising and feature extraction.
- Creation of VoiceReID custom model via PyTorch and TensorFlow.
- NLP algorithms for speech-to-text transcription, utilizing part-of-speech tagging and word sense disambiguation.
- Utilizing Gensim and NLTK for text summarization, tokenization, stemming, lemmatization, part-of-speech tagging, parsing
- Applied named entity recognition to identify named entities in text data and categorize them into predefined classes
Tech Stack: Python, pyannote, Kaldi, NLP, AWS Sagemaker, EC2, S3, Lambda, NumPy, TensorFlow, LSTM, Scikit-learn, NLTK, Spacy, Gensim, CoreNLP, Transformers, Hugging Face, Pandas, SQL, FastAPI, Git, Bash, VS Code, Unittest, Poetry.